Alors que nous faisons face aux limitations de la science des données centrée sur le cloud, notamment les préoccupations concernant la confidentialité et la sécurité des données, ainsi que les coûts et la consommation d’énergie élevés, le besoin de paradigmes innovants devient évident. Le Edge Computing et l’Apprentissage Distribué s’imposent comme des approches révolutionnaires qui décentralisent le traitement des données et réduisent la dépendance aux infrastructures cloud centralisées. Cet article explore les avantages de déplacer le calcul vers la source des données et les défis émergents associés à ce changement, en soulignant comment des plateformes telles que Manta facilitent cette transition.
L’Émergence du Edge Computing
Le Edge Computing a transformé notre manière d’aborder le traitement des données en rapprochant le calcul de l’endroit où les données sont générées. Ce changement de paradigme a été rendu possible grâce à des avancées clés :
- Capacités accrues des dispositifs : Les appareils modernes, tels que les cartes Raspberry Pi et les modules NVIDIA Jetson, offrent une puissance de calcul significative dans des formats compacts et abordables. Ces dispositifs peuvent exécuter localement des modèles d’apprentissage automatique complexes, ce qui les rend idéaux pour des applications nécessitant un traitement sur site, comme la robotique, les caméras intelligentes et les solutions IoT.
- Amélioration des solutions de stockage : La capacité de stockage accrue des appareils en périphérie permet le traitement et l’analyse de volumes importants de données localement.
- Avancées technologiques des réseaux : L’émergence des réseaux à haute vitesse, tels que la 5G, a permis des transferts de données rapides, réduisant la latence et favorisant les applications en temps réel.
Ces avancées permettent des applications dans divers équipements :
- Smartphones : Le traitement localisé des données pour les prédictions de texte et la reconnaissance vocale préserve la confidentialité des utilisateurs.
- Appareils de santé portables : Le traitement en temps réel des métriques de santé fournit des retours immédiats cruciaux pour le suivi des patients.
- Villes intelligentes : Les infrastructures utilisant le Edge Computing optimisent la gestion du trafic, de l’énergie et de la sécurité publique grâce à l’analyse rapide des données sur site.
- IoT industriel : Le Edge Computing facilite la surveillance des équipements, la maintenance prédictive et l’optimisation des processus de production.
- Véhicules autonomes : Les voitures autonomes s’appuient sur le Edge Computing pour traiter en temps réel les données de multiples capteurs, prenant des décisions instantanées pour assurer une navigation sûre et efficace sans les délais liés au cloud.
- Sondes réseau : Les dispositifs en périphérie analysent localement le trafic réseau pour détecter les anomalies, optimiser les performances et améliorer la cybersécurité en réagissant rapidement aux menaces, tout en conservant la confidentialité des données.
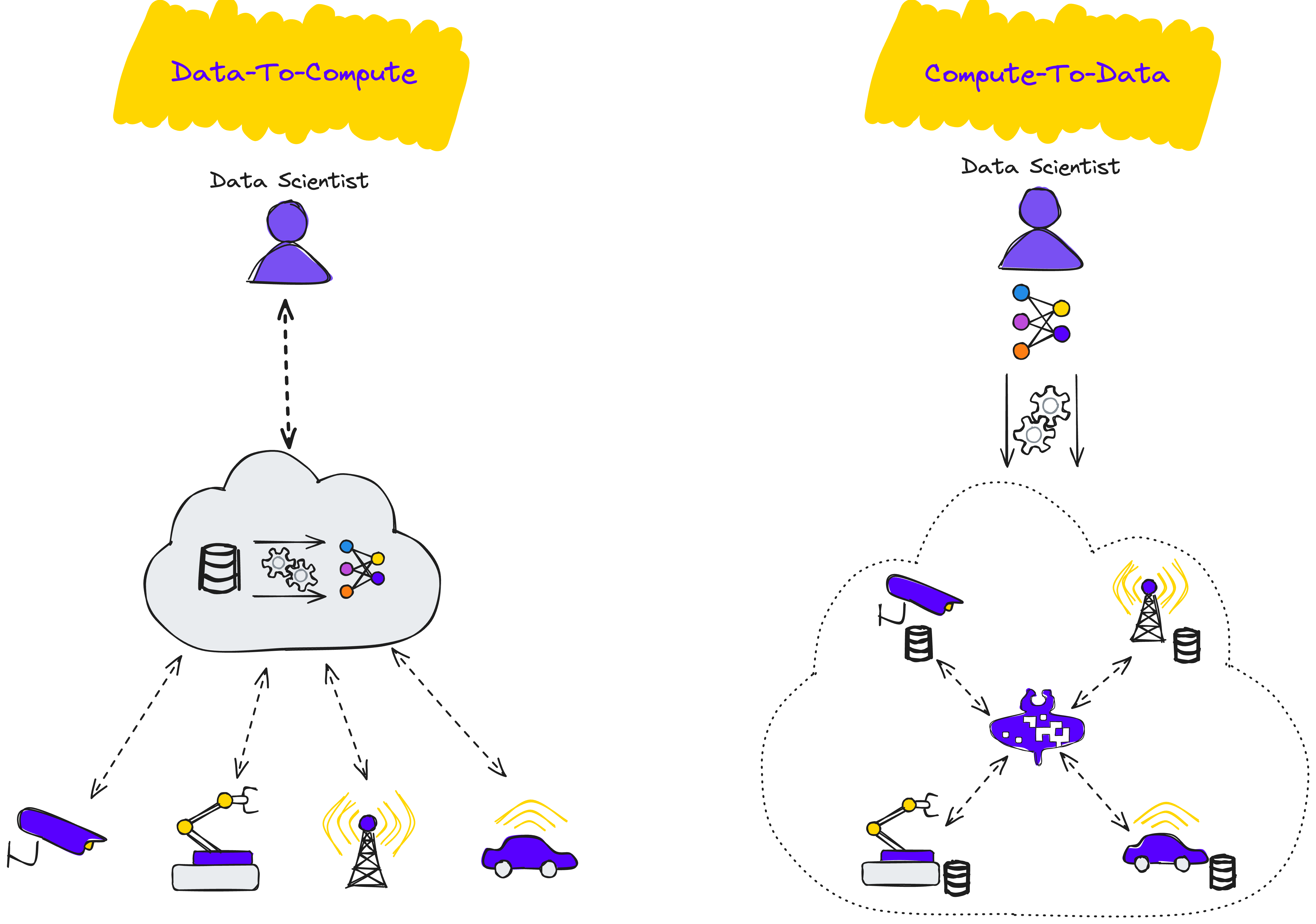
Le Traitement Décentralisé et Collaboratif
Le passage du traitement centralisé des données à des approches décentralisées a marqué des étapes importantes. À l’origine, le calcul distribué dans les centres de données permettait de paralléliser les tâches pour accélérer les processus d’apprentissage automatique. Au fil du temps, de nouveaux modèles ont émergé pour répondre aux préoccupations liées à la confidentialité des données et aux contraintes logistiques, menant au développement de l’Apprentissage Fédéré (FL).
Explication de l’Apprentissage Fédéré
Pour une exploration détaillée des procédures et principes fondamentaux de l’Apprentissage Fédéré, consultez notre article complet “Démystifier l’Apprentissage Fédéré.”
L’Apprentissage Fédéré entraîne des modèles sur plusieurs dispositifs décentralisés, chacun conservant ses données localement, sans que celles-ci soient déplacées vers un serveur central. Cette approche présente des avantages notables :
- Confidentialité des données : Les informations sensibles restent sur le dispositif d’origine, respectant les réglementations sur la vie privée et les attentes des utilisateurs.
- Efficacité de la bande passante : Seules les mises à jour des modèles, et non les données brutes, sont transmises, réduisant ainsi la charge du réseau et la latence.
- Potentiel collaboratif : Les organisations peuvent entraîner des modèles de manière collaborative en utilisant des résultats combinés tout en maintenant la souveraineté des données.
Malgré ces avantages, l’Apprentissage Fédéré présente des défis :
- Gestion des données non-IID : La répartition des données dans les dispositifs est souvent non uniforme, ce qui complique l’entraînement des modèles et leurs performances. Pour une compréhension approfondie des défis posés par les données non-IID dans l’Apprentissage Fédéré, consultez notre article détaillé sur le sujet : Apprentissage Fédéré en contexte de données non-IID.
- Problèmes de sécurité : Protéger les modèles contre les attaques de type empoisonnement et garantir une communication sécurisée est crucial pour maintenir la confiance.
- Cohérence des modèles : La coordination des mises à jour provenant de sources diverses peut introduire de la complexité dans l’obtention d’un comportement cohérent des modèles.
Pour adopter pleinement des approches décentralisées et collaboratives telles que l’Apprentissage Fédéré, des logiciels spécialisés sont nécessaires pour prendre en charge et déployer l’ensemble du pipeline MLOps — de la collecte des données à la mise en production du modèle — directement sur des dispositifs embarqués tels que les Raspberry Pi et les NVIDIA Jetson. Cette capacité garantit que ces systèmes peuvent gérer le traitement des données et l’entraînement des modèles localement, facilitant ainsi des déploiements évolutifs, respectueux de la vie privée et efficaces.
Introduction au FedOps : Une Nouvelle Ère des MLOps
Pour surmonter les complexités opérationnelles de l’apprentissage décentralisé, le paradigme FedOps (Federated Operations) a vu le jour. FedOps adapte les stratégies traditionnelles de MLOps aux environnements décentralisés et collaboratifs, permettant le déploiement fluide des pipelines d’apprentissage automatique dans des contextes distribués.
La plateforme Manta incarne cette vision en simplifiant le processus pour les data scientists — de la phase de développement du prototype à celle de la mise en production — tout en offrant la flexibilité nécessaire pour innover. En permettant le traitement décentralisé des données sur plusieurs dispositifs, Manta améliore la scalabilité, l’efficacité et la confidentialité, se positionnant comme un acteur clé de l’avenir de la science des données.
Surmonter les Défis et Libérer le Potentiel
Développer une plateforme qui soutient efficacement la science des données décentralisée nécessite de se concentrer sur la sécurité, la fiabilité et la gestion des ressources. L’approche de Manta face à ces défis met en avant :
- Des mesures de sécurité robustes : Protéger les modèles et les données pendant l’entraînement et le déploiement.
- Des protocoles de communication efficaces : Rationaliser les mises à jour des modèles sur les dispositifs tout en réduisant la latence.
- Flexibilité et scalabilité : Offrir des outils permettant aux data scientists de concevoir, tester et affiner des modèles dans des écosystèmes décentralisés.
- Complexité de la gestion des logs et des traces : La gestion des journaux et des traces dans des systèmes décentralisés peut être complexe, surtout lorsque de multiples dispositifs sont impliqués. Cette complexité peut avoir un impact significatif sur l’utilisation de la bande passante, car le suivi et l’agrégation de ces données nécessitent des transferts fréquents et potentiellement volumineux. Il est crucial de développer des stratégies de gestion optimisées pour minimiser l’empreinte sur la bande passante tout en garantissant la traçabilité et la surveillance efficace du système.
En conclusion, le passage d’un paradigme de données centralisé à un paradigme décentralisé apporte à la fois des opportunités et des défis. Le Edge Computing et l’Apprentissage Fédéré ouvrent la voie à des pratiques de science des données évolutives, respectueuses de la vie privée et efficaces. Grâce à des plateformes telles que Manta, les organisations peuvent exploiter pleinement le potentiel de la science des données décentralisée, favorisant l’innovation tout en maintenant le contrôle sur les ressources et les données.
En comprenant et en relevant ces complexités, les data scientists et les organisations peuvent débloquer de nouvelles possibilités qui stimulent les progrès dans un cadre respectueux de la vie privée et rentable.