As we navigate the limitations of cloud-centric data science—ranging from data privacy and security concerns to high costs and energy demands—the need for innovative paradigms becomes evident. Enter Edge Computing and Distributed Learning: groundbreaking approaches that decentralize data processing and reduce reliance on central cloud infrastructure. This article explores the advantages of shifting computation to the data source and the emerging challenges that accompany this shift, highlighting how platforms like Manta facilitate this transition.
The Emergence of Edge Computing
Edge Computing has transformed how we approach data processing by moving computation closer to where data is generated. This paradigm shift has been driven by key advancements:
- Enhanced Device Capabilities: Modern devices, such as Raspberry Pi boards and NVIDIA Jetson modules, provide significant computational power in compact, affordable packages. These devices can run complex machine learning models locally, making them ideal for applications requiring on-site processing, like robotics, smart cameras, and IoT solutions.
- Improved Storage Solutions: Increased storage capacity in edge devices supports the processing and analysis of substantial data volumes on-site.
- Advances in Network Technology: The development of high-speed networks like 5G has made rapid data transfer possible, reducing latency and supporting real-time applications.
These advancements enable applications across various devices:
- Smartphones: Localized data processing in predictive text and voice recognition preserves user privacy.
- Wearable Health Devices: Real-time processing of health metrics provides immediate feedback crucial for patient care.
- Smart Cities: Infrastructure powered by edge computing optimizes traffic, energy management, and public safety through rapid, on-site data analysis.
- Industrial IoT: Edge computing facilitates equipment monitoring, predictive maintenance, and efficient production processes.
- Autonomous Vehicles: Self-driving cars rely on edge computing for real-time data processing from multiple sensors to make split-second decisions, ensuring safe and efficient navigation without the delays of cloud-based computation.
- Network Probes: Edge devices monitor and analyze network traffic locally to detect anomalies, optimize performance, and enhance cybersecurity by responding to threats swiftly and maintaining data privacy.
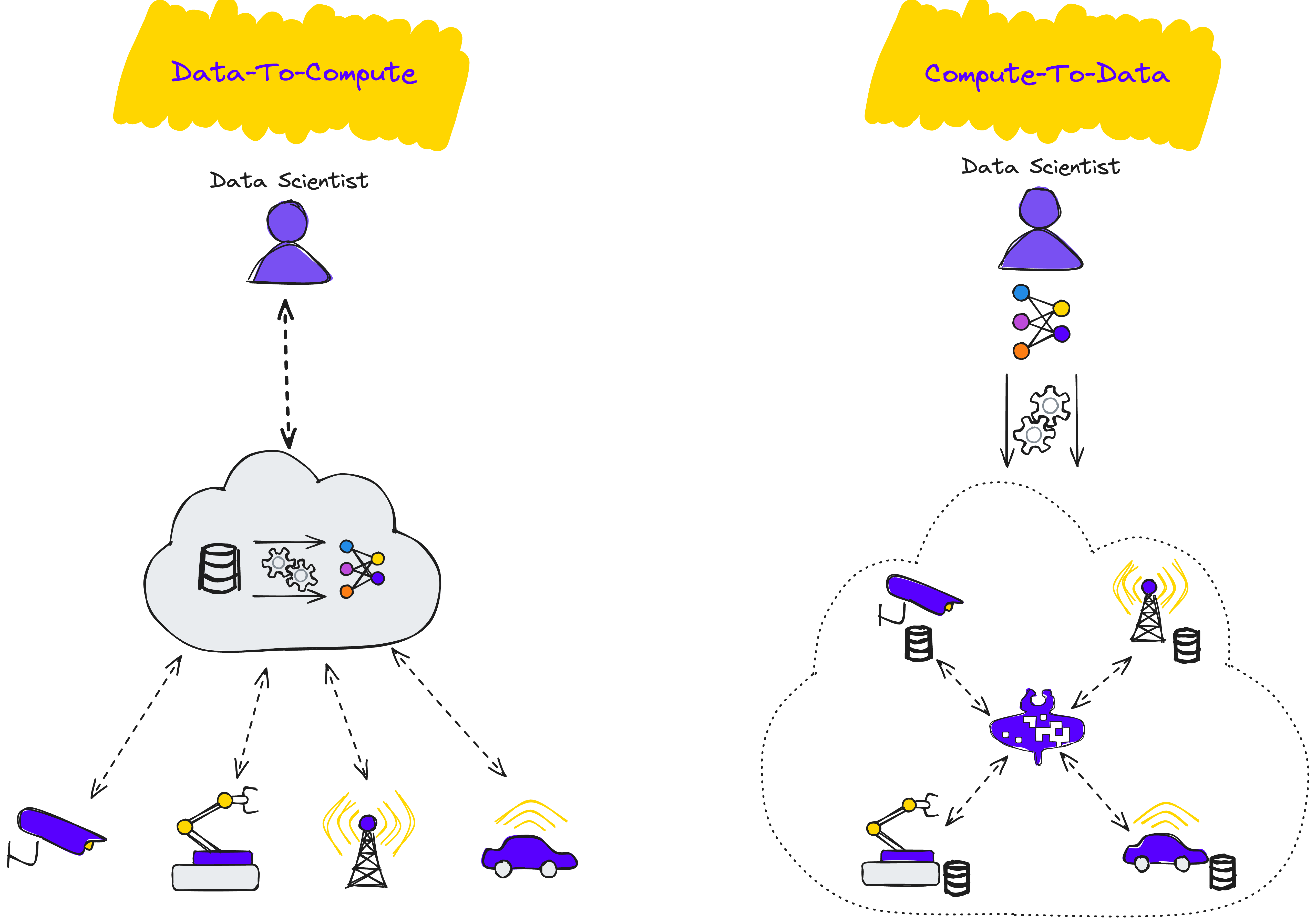
Decentralized and Collaborative Processing
The journey from centralized data processing to decentralized approaches has seen significant milestones. Initially, distributed computing in data centers allowed the parallelization of tasks to expedite machine learning processes. Over time, new models emerged to address data privacy and logistical issues, leading to the development of Federated Learning (FL).
Federated Learning Explained
For an in-depth exploration of the Federated Learning process and its foundational principles, refer to our comprehensive article “Demystifying Federated Learning.”
Federated Learning trains models across multiple decentralized devices, each with local data, without moving that data to a central server. This approach offers notable benefits:
- Data Privacy: Sensitive information remains on the originating device, meeting privacy regulations and user expectations.
- Bandwidth Efficiency: Only model updates, not raw data, are transmitted, reducing network load and latency.
- Collaborative Potential: Organizations can collaboratively train models using combined insights while maintaining data sovereignty.
Despite these advantages, Federated Learning presents challenges:
- Non-IID Data Handling: Real-world data distribution across devices is often non-uniform, complicating model training and performance. For a deeper understanding of the challenges posed by non-IID data in Federated Learning, refer to our detailed article on the topic: Federated Learning in Non-IID Data Contexts.
- Security Concerns: Safeguarding models against poisoning attacks and ensuring secure communication are vital to maintaining trust.
- Model Consistency: Coordinating updates from diverse sources can introduce complexity in achieving consistent model behavior.
To achieve full adoption of decentralized and collaborative approaches like Federated Learning, specialized software is needed to support and deploy the entire MLOps pipeline—from data collection to model production—directly on embedded devices such as Raspberry Pi and NVIDIA Jetson. This capability ensures that these systems can handle data processing and model training locally, facilitating scalable, privacy-preserving, and efficient deployments.
Introducing FedOps: A New Era of MLOps
To address the operational complexities of decentralized learning, the FedOps (Federated Operations) paradigm has emerged. FedOps adapts traditional MLOps strategies for decentralized and collaborative environments, supporting the seamless deployment of machine learning pipelines in distributed settings.
Manta’s platform embodies this vision by simplifying the process for data scientists—from prototype development to production deployment—while offering the flexibility to innovate. By enabling decentralized data processing across devices, Manta enhances scalability, efficiency, and privacy, positioning itself as a key enabler of the future of data science.
Overcoming Challenges and Unlocking Potential
Developing a platform that effectively supports decentralized data science necessitates a focus on security, reliability, and resource management. Manta’s approach to these challenges emphasizes:
- Robust Security Measures: Ensuring the protection of models and data during training and deployment.
- Efficient Communication Protocols: Streamlining model updates across devices while mitigating latency.
- Flexibility and Scalability: Providing tools that empower data scientists to design, test, and refine models within decentralized ecosystems.
- Complexity of managing logs and traces: Handling logs and traces in decentralized systems can be challenging, especially when multiple devices are involved. This complexity can significantly impact bandwidth usage, as tracking and aggregating these logs often require frequent and potentially large data transfers. Developing optimized management strategies is essential to minimize bandwidth footprint while ensuring effective system traceability and monitoring.
In conclusion, the shift from a centralized data paradigm to a decentralized one brings both opportunities and challenges. Edge Computing and Federated Learning pave the way for scalable, privacy-preserving, and efficient data science practices. With platforms like Manta, organizations can harness the full potential of decentralized data science, fostering innovation while maintaining control over resources and data.
By understanding and addressing these complexities, data scientists and organizations alike can unlock new possibilities that drive progress in a privacy-conscious, cost-effective manner.